Condition Monitoring Expert Tip #1 by Mobius Institute
This tip is sponsored by IMVAC (International Machine Vibration Analysis Conference)
How do you decide which condition monitoring technologies to use?
There are many condition monitoring technologies that we could employ. And within each technology there are sub-technologies. For example, within vibration analysis, we can use high-frequency analysis, spectrum analysis, time waveform analysis, and phase analysis. Within each sub-technology, there are settings we must select. For example, we must set the frequency range when collecting spectra. But which technologies should we use? Which settings are correct? The best way to make those decisions is by understanding the failure modes of the equipment.
If you understand what leads to failure, and what is likely to fail, you can select the most appropriate technologies and settings. You may argue that that is an obvious statement to make. You are probably not using vibration analysis on your steam traps… But after 30 years of experience in vibration analysis, it is common to see that fault conditions a totally missed because of the misapplication of the technology.
It is not necessary to perform a full RCM (reliability-centered maintenance) or FMEA (failure modes effects analysis) to make this determination. A so-called “accelerated RCM” is sufficient to ensure that you make the right decisions.
Special thanks to Mobius Institute for allowing us to share this condition monitoring expert tip with you!
by Ana Maria Delgado, CRL
There are two commonly used testing methods to determine a vertical pump’s natural frequency. The first method is called a startup or coast down. In order to perform this method, a tach signal is required for the speed to be tracked. The pump is started and the amplitude and phase are recorded during start-up and coast down, however, when a pump is started across the line (connected directly to a power source without a drive or soft-start circuit) it is very difficult to use this method. The problem is that when a pump is started across the line it goes from zero rpm to full speed so quickly that there is not enough time to obtain valid data. The coast down method is not normally successful in these cases. When the stop is initiated the pump comes to a complete stop in a very short period of time as the liquid inside the pump column falls back to the wet well acting as a brake. However, start-up and coast-down testing can be performed successfully if a pump is being operated using a VFD (Variable Frequency Drive) as the rate of speed can be controlled.
The other method of determining structural natural frequencies on a vertical pump is to conduct an impact test. This test is more commonly known as a bump test. This test requires that the pump be stopped and impacted using a block of wood or a large hammer that has a soft tip (modal hammer). The bump test provides a response curve that will identify the natural frequency and/or frequencies of the pump. It is recommended that the testing be performed in two separate directions. One direction would be in-line with the pump’s discharge pipe and the other direction should be 90 degrees from the discharge pipe. The two different directions will usually result in two different natural frequencies as the pump’s discharge pipe tends to stiffen the structure. This vibration data can be shown as a higher natural frequency from that direction. The other direction which is 90 degrees from the pump discharge will usually have a lower natural frequency. This is due to the fact that the pump manufacturers typically cut out part of the structure. This allows access to the coupling or seal which also dampens the structure in that direction.
Both of the mentioned methods can assist with discovering the natural frequencies of a pump. Once the frequencies have been identified on the pump; the proper corrections can be made to make certain that the pump is not operating on a resonance frequency.
Learn more about our Condition Monitoring tools
by Dave Leach CRL CMRT CMRP
In today’s modern world information is found all around us and it is available at the simple push of a button; 24/7/365. Machine condition monitoring systems (online systems) have been around for quite a while, but they have typically been reserved for the most critical and most expensive machines at a facility. These critical assets typically comprise a small number of the total assets at most manufacturing plants. The majority of machines fall under the walk-around monitoring approach. If a condition monitoring program is being conducted at a world-class level then each machine is being tested monthly, however, at most manufacturing facilities manpower constraints restrict monitoring to quarterly or in some cases once or twice a year. Machines that have been historically confined to a walk-around type program can now be monitored successfully using an online system.
These systems can monitor and trend vibration levels as well as monitor and trend ultrasound and temperature.
The online systems can be configured to deliver a machine’s alarm status directly to the plant process control system. This allows the machine operator to take the necessary corrective actions. The alarm status can also be delivered to a maintenance supervisor via cell phone message or email. Using online systems to monitor the health status of your process equipment will allow the identification of problems early with minimal manpower so that catastrophic failures can be prevented which ultimately leads to less machine downtime for repairs and increased cost savings.
by Dave Leach CRL CMRT CMRP
Comments that I have heard in all types of industry are “We always have the time or money to do the repair over, but never time or money to do it right”. Many times when equipment fails there is an incredible rush to get the machine back online due to some production requirement. This usually leads to repairs that are inadequate or incomplete. It is important to remember that as long as your lock is on the machine it is not going to go back into service until you remove that lock. It could take as little as an additional 30 minutes to allow the machine to be repaired completely, but instead, the job is rushed and a few weeks or a couple of months later the same machine is being repaired for the same reasons again.
Production controls the purse strings that is a given, but generally, product quality and maintenance cost can be better controlled by allowing for a complete repair, not a partial fix. A couple of examples that come to mind are belt-driven machines. Many repair techs simply roll V-belts on and off for removal or installation. Have you ever noticed a V-belt running upside down? In most cases, it is due to the cords in the backing of the belt being broken. This is usually caused by rolling the belts on or off the sheave. If “power band belts” are used the cost of those belts is usually higher than the sheaves that the belts are running on. It is a paradox that brand new belts will be installed on worn-out sheaves.
When the sheaves are replaced most of the sheaves are affixed to the shaft with a taper lock hub. How many people use an indicator to ensure that the sheaves are square to the shaft and not just tighten the hub with an impact wrench? There are others examples, but hopefully, this drives the point home. Repairs need to be done in a timely fashion in cooperation with production to minimize downtime and reduce any effects on quality.
by Gary James CRL
First and foremost vibration data setups must be properly configured to allow the correct results to be collected thus allowing the analyst to interpret the vibration data for defects. The defect findings should be presented in a manner that the personnel that is responsible for the repair of the equipment now have the necessary information to perform their intended function. The vibration data alone will not fix anything. A vibration database must have the proper setups, the vibration data must be collected correctly using the appropriate instrument, and analyzed by a properly trained and confident analyst. This allows for the root cause of the problem to be found as opposed to only replacing parts. It is very critical that the correct person becomes the vibration analyst. This person should have the desire and drive to become the best that they can become at that position. The analyst should also have support from upper management to allow them to focus on one job.
With the right people, right tools, and support you will have the meaningful data to drive and sustain valuable results and continuous improvement.
by Gary James CRL
As Published by COMPRESSORtech2 Magazine October 2016 issue
by Karl Hoffower – Condition Monitoring and Reliability Expert for Failure Prevention Associates
Combining ultrasound and vibration sensing adds precision to recip valve analyses
Over the past decade, ultrasonic condition monitoring of reciprocal compressor valves has become more widely known. However, it does not seem to be widely used.
Ultrasonic testing measures high-frequency sound waves, well above the range of human hearing.
These ultrasound devices record the high-frequency signals for analysis later. Trending valve cap temperatures is the most common condition monitoring technique for monitoring
compressor valve health.
Ultrasonic testing of compressor valves and vibration monitoring of rotating components is an informative, preventative-maintenance practice. Compressor valve deficiencies with opening, closing, or leaking may be diagnosed using the ultrasound recording functions.
Steven Schultheis, a Shell Oil Co. engineer, addressed the issue in a paper presented at the 36th Turbomachinery Symposium in Houston in 2007.
“Trending valve temperatures have proven to be valuable in identifying individual valve problems, but are most effective if the measurement is made in a thermowell in the valve cover.” Schultheis wrote. “Ultrasound has proven to be the preferred approach to the analysis of valve condition.”
Failure Prevention Associates completed an experiment with a major midstream gas transmission company to see if this type of condition monitoring tool can effectively find fault conditions well before another technology is used.
Ultrasound meters (such as the SDT270 from SDT Ultrasound Solutions) have digital readouts that indicate the level of ultrasound detected. These devices have been used for decades to “hear” air, gas, and vacuum leaks. The intensity or amplitude of the signal is expressed in decibels — microvolts. (dB[A] μV). The dB(A) is a common intensity unit for sound intensity; μV designates the engineering reference unit being used with a piezoelectric sensor.
Converting an airborne ultrasound detector with a contact sensor allows a technician to monitor what is happening inside a machine, whether it is a bearing, steam trap, or valve.
Ultrasound detectors are designed to operate in a specific and narrow frequency band. Then through the “heterodyning” step high frequency sounds down into an audible format that the technician can hear through headphones. During the heterodyning process, the quality and characteristics of the original ultrasound signal are preserved.
Read full article complementary-condition-monitoring-boosts-reliability-article
by Yolanda Lopez
Proper equipment function requires a properly aligned and balanced machine. Allowing a machine to operate with an unbalance condition can result in bearing damage, cracks, loose components, and many other costly maintenance issues. Loose debris can dislodge and impact the balance quality of a machine. Debris buildup on the impellers/blades, and other rotating parts can create unbalance conditions. Before balancing the machine it is very important that the rotating surfaces (blades, etc.) are cleaned of any debris. Removing buildup will help ensure that the machine can be properly balanced and remains in a balanced condition.
by Trent Phillips CRL CMRP - Novelis
As Published by Maintenance Technology Magazine August 2016 issue
Clinging to a single approach that made economic sense for your plant ‘back in the day’ could be an expensive strategy.”
Overall values are the most common measurements and calculations used in vibration analysis. What’s more, some reliability and maintenance programs rely solely on them. The goal is to remove monitored equipment from service once the overall vibration level exceeds a certain threshold. Although this approach would appear to be quite cost-effective, in reality, it frequently isn’t. In fact, overall vibration monitoring can become extremely costly for a facility.
If you are asking yourself questions such as: What should you do once an overall vibration level exceeds your target amplitude and the equipment is removed from service? Who should collect routine vibration data? What other valuable condition-monitoring data might be missing? Or how do you motivate others to take corrective actions? then this article is definitely a must-read.
by Trent Phillips CRL CMRP - Novelis
The maintenance and reliability world is filled with key performance indicators (KPIs). Properly tracking KPIs can be challenging due to difficulties in obtaining accurate data and the time required to obtain them. The key is to pick KPIs that will help you identify and drive the behavior that you need to change right now. As advances are made, additional KPIs can be added which help identify and drive additional behavior changes and improvements.
It is very important to understand that KPIs can lead to false-positive indications and never actually result in value-added or sustainable improvements within your organization. You must understand and address the true root causes behind a deficient KPI and eliminate them.
For example, mean time to repair (MTTR) can be a very good indicator leading to great improvements.
Unfortunately, this indicator can also be harmful if misunderstood or given the wrong improvement focus. What if individuals decide to take deleterious shortcuts to quickly get a machine operational again? MTTR may seem to improve on that machine, but did overall asset health and reliability really improve, in a meaningful way that provides real value back to your organization? These shortcuts may actually lead to additional machinery failures and greater downtime.
MTTR could be an indication that maintenance staff requires training on how to properly repair the machine. Too short and perhaps unwanted shortcuts are being taken. Too long may indicate that excessive time is being wasted hunting for tools or spare parts due to a lack of proper planning and/or kitting. Is a detailed and efficient work plan available, to guide your maintenance staff incorrectly repairing the equipment? MTTR, if properly used and tracked can point you toward areas of substantial improvement.
Never forget to determine and address the root causes of equipment failure. Doing so may eliminate the need to work on the equipment in the first place. Prevention is always the best way to drive sustainable improvements in uptime and capacity.
Beware of driving improvements in KPIs for the wrong reasons. This can lead to a false sense of progress that never brings about real changes and advancements in reliability to your organization. Ensure that you understand the real variables driving the KPIs you have selected. Don’t let your chosen KPIs give you a false sense of improvement!
by Trent Phillips CRL CMRP - Novelis
How do you obtain the desired return on your assets? Availability, maintainability, and reliability are foundational elements required for a proper return on your equipment. Condition Monitoring is a tool that can help you build these elements and obtain the desired returns. Condition Monitoring can be completed while equipment is running to maximize uptime and help provide better overall reliability. Conditional changes can be identified before functional failures that result in downtime occur, preventing other unwanted consequences.
Unneeded work can be avoided (unnecessary PMs, failures, etc.), and better planning and improved scheduling achieved through CM.
Use Condition Monitoring as a means to build a solid foundation for your facility!
by Trent Phillips CRL CMRP - Novelis
Companies spend lots of money, time, and effort on systems to document what needs to be done, what should have been done, failures that occurred, etc. Unfortunately, these systems usually show and document the point of failure (F) and not the point of conception (P) for a problem. These are examples of downtime systems and are important for success.
Does your company invest in uptime systems and processes? What is an uptime system or process? These systems help your facility identify the point of conception (P) of a problem. This is very important because it means your facility has more time to mitigate a problem before it results in unwanted consequences (injury, downtime, increased costs, poor quality, less main profit, etc.)
Condition monitoring (CM), reliability efforts, proper planning, and scheduling, kitting, effective PMs, reliability-based engineering, etc., will reduce the amount of information that must be entered and tracked through the downtime systems that have been heavily invested in. The results can be extremely rewarding.
What uptime systems and processes does your facility utilize?
by Trent Phillips CRL CMRP - Novelis
March 2016 · Empowering Pumps Magazine
“Work smarter, not harder” is a statement we have all heard before, but who has the time to think about smarter ways to work when there is so much work to be done? Some maintenance professionals are so busy trying to keep their operation running smoothly that they often address equipment issues “reactively”. This might make maintenance teams feel more like “firemen” as they respond to in-the-moment needs. So how does a company become less “reactive” and more “proactive”?
Read the full article: Maximize Uptime with Asset Condition Management to better understand the key components of an Asset Condition Management (ACM) Program and how core technologies like Alignment, Balancing Vibration Analysis, and Ultrasound Testing can help you increase uptime.
by Dave Leach CRL CMRT CMRP
May 2016 · Plant Services Magazine
Like a lot of reliability engineers, Joe Anderson, former reliability manager at the J.M. Smucker Co., appreciated – in theory – that precise pulley alignment is critical to preventing vibration problems and ensuring successful operations.
My understanding was, ‘Yeah, we need to do it,’ ” Anderson says. “But you always have these excuses.”
When the Smucker’s plant at which Anderson worked launched a dedicated vibration monitoring and control program a year-and-a-half ago, though, Anderson quickly became a convert to making precision alignment a priority.
The plant purchased a vibration analyzer (VIBXPERT®) and laser alignment tool (the SheaveMaster® Greenline) from Ludeca to help aid in identifying machine defects that appeared to be linked to vibration caused by misalignment. Laser alignment allowed for correcting vertical angularity, horizontal angularity, and axial offset – the three types of misalignment – simultaneously. Whoever was using the laser alignment tool, then, could be sure that adjustments made to correct one alignment problem didn’t create an issue on another plane.
Read the entire article to learn how J.M. Smucker Co. made precision alignment a priority: Get your alignment in line: Don’t jiggle while you work
by Ana Maria Delgado, CRL
Guest post by Karl Hoffower – Condition Monitoring and Reliability Expert for Failure Prevention Associates
Location and placement of your sensors are crucially important when doing predictive vibration analysis.
1) Below is an example of proper sensor installation on a cooling tower gearbox. These two sensors are placed in different directions to follow both the gearbox vibration as well as indicate if the fan blades become unbalanced.

Read Vibration Sensors for Cooling Towers case study from CTC for details on proper sensor installation on cooling towers.
2) This example of poor sensor placement is on a vertical motor using a belt drive for a fin fan.

PROBLEM
- The vibration sensors pictured on the left are attached to one of the motor fins. Watching these sensors, one could visually see the fin and sensors oscillating as if on a trampoline.
SOLUTION
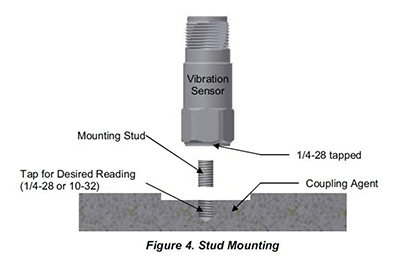
- The choices are to face, drill & tap (see figure #4 below).
- The other option would be to epoxy a mounting pad to the bearing housings. Then screw the sensor into the mounting pad.
3) Another example of poor sensor placement on a 4-20mA shutdown switch on a gas recipient compressor at a facility in Texas.

PROBLEM
{kind=link}
- The vibration sensor (yellow arrow) is a 4-20mA accelerometer used for asset protection in an automatic shutdown setting. It is monitoring the overall vibration levels emanating from the bearings and shaft (red arrow).
SOLUTION
- The better choice would be to use a mounting pad attached to the pillow block bearing.
by Yolanda Lopez
Does your maintenance staff have to wait on parts, wait for the equipment to be available, search for tools to do their job, work lots of overtime, travel long distances to the job, etc? Most maintenance staff work in pairs. This means that when you see one of your maintenance staff struggling to do his job, then his counterpart is struggling as well. What is the result? You may have a hidden cost (twice the labor) that you did not realize!
What can you do to avoid this? Make sure that your work is correctly planned. Job plans should be created, and be accurate and available. The required parts should be staged once the work is planned. Machine drawings, special tools, permits, etc., required to complete the maintenance activity should be identified in the job plan and be available as part of the job kit. Once all of this is done the work should be scheduled. These steps will help your maintenance staff focus on work and not on searching for the resources they need to complete their assigned maintenance tasks. You will save money and have more reliable equipment.
by Trent Phillips CRL CMRP - Novelis
Did you know that equipment PMs (Preventive Maintenance) tend to become more expensive over time? Why does this happen? For example, additional maintenance steps tend to be added to a PM as time passes. The machine configuration (design installation) changes and the PMs are never updated to reflect these modifications. Some PMs are not written correctly in the first place. All of this means that unnecessary maintenance is performed on your machines costing a lot of resources and money for a very long time. These are just some of the reasons PMs can be costly.
RCM and FMEA functions usually cost more money upfront and tend to be avoided as a result. However, these functions can clearly identify what maintenance actions should be performed on equipment and guide you to steps that will avoid maintenance issues. Condition Monitoring is another tool that works directly with RCM and FMEA functions to reduce PM activities and drive better equipment performance and reliability. These activities may cost more upfront versus a PM but will be much more cost-effective in the long run.
by Trent Phillips CRL CMRP - Novelis
Can a Reliability Engineer or Reliability Manager make a facility or organization reliable? This is a very important question that may be worth discussing within your organization to ensure proper expectations and success.
A more practical definition of reliability may be:
Equipment performs the way you want it to when you want it to”.
Reliability is very easy to define, stuff but achievement of this simple goal is complex and unfortunately unattainable for many organizations. Reliability requires a holistic approach that involves the complex interaction of Maintenance, see Operations, Supply Chain, Engineering, Procurement, Management, Process, and Vendors. Consistency, focus, and strategic implementation directly correlate to the success of any effort and this is true for your reliability efforts. Therefore, a consistent and strategic top-down focus is required from management and throughout each of these groups. Organizational misalignment leads to competing groups and will make sustainable reliability within your organization extremely difficult, and maybe even impossible to achieve.
Reliability Engineers and Managers can support reliability through leadership, training, tools, etc. However, the answer to the question is that everyone within your organization is responsible for reliability. It is critical that everyone within an organization understands this and that reliability is made a goal for each of these groups with defined metrics to track understanding and achievement.
So, who owns equipment reliability in your plant? The answer is Everyone!
by Trent Phillips CRL CMRP - Novelis
Most companies focus on repairing equipment after some functional failure has occurred and getting the equipment operational again. Is that the primary focus of your facility? Different studies have been completed by different organizations, which, while the percentages are different, all point to some very consistent and vital information. Design (engineering), installation (contractors, internal resources) and operation of the equipment all introduce equipment defects and drive reliability in your facility. Maintenance cannot overcome poor design, installation, and operation. Your maintenance staff can only deal with (repair) the consequences.
Your reliability efforts should be focused on preventing the introduction of defects in your equipment. This will help ensure equipment reliability leading to lower maintenance costs, increased capacity, and other positive results. Ensure that your equipment is designed, installed, and operated with reliability in mind. Make sure that you focus on the prevention and elimination of equipment defects as well.
by Trent Phillips CRL CMRP - Novelis
Maintenance and reliability professionals track many key performance indicators (KPI’s) to measure the success of their efforts. These indicators can be overwhelming but are necessary to confirm the proper direction and achievement of desired results.
It is important that your CMMS (computerized maintenance management system) has the ability to categorize work orders. Condition monitoring work orders should be categorized by main types and by sub-types (vibration, lubrication, thermography, ultrasonic, electrical, etc.) upon creation within the CMMS.
Your CM and Reliability team should actively track condition monitoring work orders by total created, their type (vibration, lubrication, etc.), status (in process, scheduled, completed, etc.), the average length of time to completion, rejection results, and so on.
These indicators will allow you to ensure that a healthy amount of CM work is available and that this work is given priority, being properly planned, scheduled, and executed. It does no good to detect and report a conditional change in equipment only to have it ignored, not properly repaired, and then result in a functional failure.
Additionally, technology alarm status can be compared to open corrective work orders in your CMMS. For example, a corrective work order should exist addressing each severe alarm condition (red) reported by a CM technology. If a corresponding work order has not been created, then you should ask “Why”? Is it due to a bad technology alarm? Did the CM analyst miss something or fail to report the condition or repair? Or did the planner or scheduler simply overlook or ignore it?
Monitoring these indicators can help ensure that your CM program is providing continual results that will move your reliability efforts forward.
What indicators do you track to determine success with condition monitoring efforts within your company?
by Trent Phillips CRL CMRP - Novelis
WIP is an acronym for “Work In Progress”. An example of WIP is when the widget must progress through different production processes that change fit form or function before reaching a stage of final completion and readiness for shipment to the end-user. Work management is required to ensure the widget moves through these stages at the proper time and under the correct conditions. Most production facilities have some type of WIP that is followed.
Maintenance activities must follow a WIP process to ensure success as well. As the graphic below illustrates maintenance work should start out as a maintenance request and progress through the critical stages shown below before competition. Each stage must be closely monitored to ensure that bottlenecks do not exist or stages are bypassed as the work is started and executed.
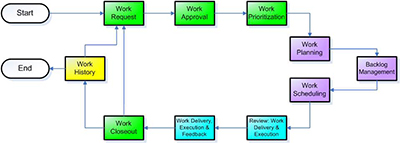
The goal is to ensure that the Right Work is done at the Right Time and in the Right Way. Feedback and work history make the final steps in the execution process to help ensure any improvements are known and implemented.
Do you WIP your maintenance process to ensure proper execution of work?
by Trent Phillips CRL CMRP - Novelis