Guest post by John Lambert at Benchmark PDM
Recently I have been seeing the P to F interval curve popping up a lot on my LinkedIn feed and in articles that I have read. It was a concept that I was first introduced to when I was implementing Reliability Centered Maintenance into the Engineering and Maintenance department at the plant where I worked at the time. It was a great idea, that if done correctly is a maintenance benefit. Why, because it’s cost savings and cost avoidance. Let me explain this.
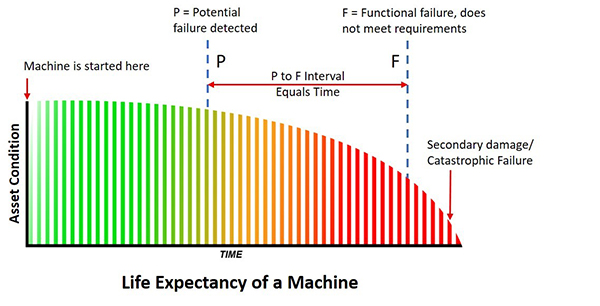
The P to F curve was used as a learning tool for Condition Based Maintenance. The curve is the life expectancy of a machine, an asset. The P is the point when a change in the condition of the machine is detected. The F is when it reaches functional failure. This means that it is not doing the job it was designed to do. For example, if it were a seal that is designed to keep fluids in and contamination out and is now leaking, it’s in a state of functional failure. Will this put the machine down? Probably not, but it depends on the importance of the seal and the application. This is an important point because the P (potential failure) is a fixed point when you detect the change in condition but the F (failure) is a moving point. Not all warnings of failure put the machine down very often you have options and time. Consider this: If I have a bucket that has a hole in it, it is in a functional failure state. But can I still use it to bail out my sinking boat? You bet I can!
Failure comes at us in many ways and obviously, we have many ways to combat it. If you detect the potential failure early enough (and it can be months and months before actual failure) it means that you can avoid the breakdown. You can schedule an outage to do a repair. It’s not a breakdown, the machine hasn’t stopped, it’s no downtime. This is cost avoidance and the plant can save on the interrupted loss of production because of downtime costs.
There are a lot of examples of cost avoidance and also of cost savings. For instance, at the plant I worked at we used ultrasound to monitor bearings. We detected a very early warning in the sound level and were able to grease the bearing and the sound level dropped. We saved the bearing of any damage, and we saved a potential breakdown so this is cost savings. Even if there is some bearing damage, the fact that we are aware of and monitor the situation lets us avoid any secondary damage.
It’s one price to replace a seal and it’s more if you have to replace a bearing in a gearbox. However, it can be very expensive to have to replace a shaft because the bearing has sized onto it and ruined it. Secondary, ancillary damage can mount up very quickly if you don’t heed the warning you are given with the P of potential failure. This warning of potential failure gives you time before any breakdown. The earlier the detection, the more time. Time to plan, and view your options. And what people tend not to do is failure analysis while the machine is still in service. A failure analysis gives you a great start on seeking out the root cause but starts right away, not when the machine is down.
Condition monitoring or as it’s often called Condition-based maintenance (CBM) does work. However, for me, there is a downside to this and I will explain why shortly. CBM is based on measurement, which is good because we all know to control a process we must measure.
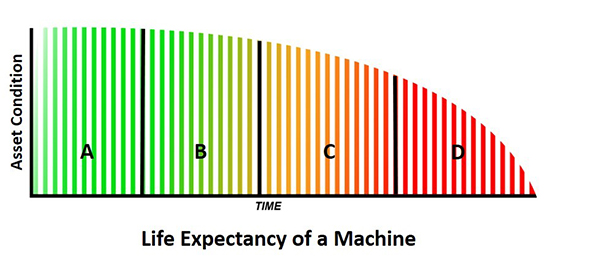
Consultants (and I’m guilty) like to put labels on things and you may see:
1. Design, Capability, Precision Maintenance
2. CBM, Predictive Maintenance
3. Preventive Maintenance
4. Run to Failure, Breakdown Maintenance
For me, the P to F interval curve starts when the machine starts. That means Design and Precision Maintenance is not in the curve and this happens before startup. A small point but it takes away from the interval meaning.
We use predictive maintenance technologies in CBM. Vibration, Ultrasonic, Infrared, Oil Analysis, NDT (i.e. pipe wall thickness), and Operational Performance. They are all very good technologies, yet it is a combination of cross-technologies that works best. As an example, vibration may give you the most information yet ultrasound may give you the earliest warning on a high-speed bearing. And then there is oil analysis which may be best for a low-speed gearbox. It all depends on the application you have which dictates what’s best for you. A lot of time and effort was placed on having the best CBM program and buying the right technology.
This, I believe, lead to the maintenance departments putting the focus on Condition-based maintenance! This I think is wrong because we still have failure. This means that CBM is no better than Predictive Maintenance. This doesn’t mean that I don’t recommend CBM, I do. To me, it’s a must-have but it does not improve the maintenance process because you still have machine failure. Machine failures fall into three categories Premature failure, Random failure, and Age-related failure. We want the latter of these. We know from studies that say that 11% of machine assets fail because of age-related issues. They grow old and wear out. This means that 89% fail because of some other fault. This is a good thing because it gives us an opportunity to do something about them.
These numbers come from a very famous study by Nowlan and Heap (Google it!) that was commissioned by the US Defense Department. It doesn’t mean these numbers are an exact reflection of every industry but the study but it has stood the test of time and I believe it has led to the development of Reliability Centered Maintenance. But let’s say it’s wrong and let us double the amount they say is age-related (full machine life expectancy). That would make it 22% and 78% would be the number of random failures. Even if we quadruple, it’s only 44% meaning random is at 56% and we are still on the wrong side of the equation. The maintenance goal has to be to get the full life expectancy for all their machine assets.
In order to get the full life expectancy for a machine unit, I think you have to be assured of two things. One is the design of the unit which includes all related parts (not just the pump but the piping as well). The other is the installation.
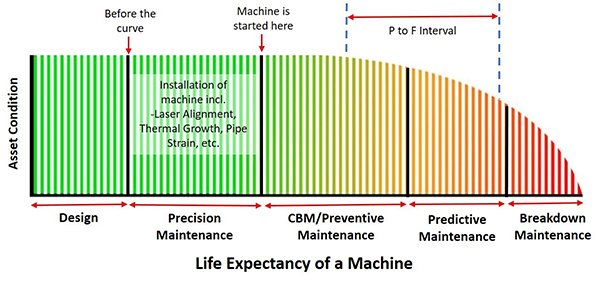
If you’re like me, and you believe that Condition Based Maintenance starts when the machine starts then you understand that there is a section of the machine’s life that happens before. You could make an argument that it starts when you buy it because, as we all know, how we store it can have an effect. However, what is important at this stage is the design and installation of the machine. In most cases, we do not design the pump, gearbox, or compressor but we do size them so that they meet the required output (hopefully). We do quite often design the piping configuration or the bases for example. All of which is very important but the reality is that maintenance departments maintain already-in-place machine assets. So, although a new installation, requiring design work is not often done, installation is. Remove and Refit is done constantly. And the installation is something that you can control. In fact, it’s the installation that has the largest influence on the machines’ life. The goal is to create a stress-free environment for the machine to run. No pipe strain, no distorted bases, no thermal expansion, no misalignment, etc.
Precision Maintenance was a term I first heard thirty years ago. It’s part of our M.A.A.D. training program (Measure, Analyse, Action, and Documentation). It’s simple, it means working to a standard. Maintenance departments can set their own standards. However, all must agree on it and adhere to it. This is the only way to control the installation process. This is the way to stop random failure and get the full life expectancy for your machine assets. The issue is that we do not have a general machinery installation standard to work to. Yes, we can use information from other specific industry sources such as the American Petroleum Institute (API) or the information from the OEM (both of these are guidelines) however nothing for the general industry as a whole. Well, this is about to change. The American National Standard Institute (ANSI) has just approved a new standard that is about to be published. I know this because I worked on it and will be writing about it shortly.
If you look at the life cycle of a machine, we need to know and manage the failure as best we can. If we only focus or mainly focus on the failure, we will not improve the reliability of the machine. We cannot control the failure. What we can control is the installation and done correctly this will improve the process giving the optimum life for the machine.
I sell laser alignment systems as well as vibration instruments. If a customer were to buy a vibration monitoring tool before they bought a laser system. I would think their focus is on the effect of the issue, not the cause. What do you think?
by Ana Maria Delgado, CRL
Condition Monitoring Expert Tip #1 by Mobius Institute
This tip is sponsored by IMVAC (International Machine Vibration Analysis Conference)
How do you decide which condition monitoring technologies to use?
There are many condition monitoring technologies that we could employ. And within each technology there are sub-technologies. For example, within vibration analysis, we can use high-frequency analysis, spectrum analysis, time waveform analysis, and phase analysis. Within each sub-technology, there are settings we must select. For example, we must set the frequency range when collecting spectra. But which technologies should we use? Which settings are correct? The best way to make those decisions is by understanding the failure modes of the equipment.
If you understand what leads to failure, and what is likely to fail, you can select the most appropriate technologies and settings. You may argue that that is an obvious statement to make. You are probably not using vibration analysis on your steam traps… But after 30 years of experience in vibration analysis, it is common to see that fault conditions a totally missed because of the misapplication of the technology.
It is not necessary to perform a full RCM (reliability-centered maintenance) or FMEA (failure modes effects analysis) to make this determination. A so-called “accelerated RCM” is sufficient to ensure that you make the right decisions.
Special thanks to Mobius Institute for allowing us to share this condition monitoring expert tip with you!
by Ana Maria Delgado, CRL
Hopefully, your company has global, regional and facility resources dedicated full time to reliability initiatives.
These resources are necessary to help ensure improvements in maintenance, equipment run-time, capacity, profits, and much more.
The question you and your organization should be asking is “who is the reliability leader in your organization”?
The answer may seem simple but could be quite surprising when given serious consideration. The answer should be “everyone”. The truth is that most implementation efforts in a facility or company fail. Unfortunately, this is very true for maintenance and reliability improvements. The reason is that not “everyone” is committed to the effort. Sustainable reliability requires understanding and dedication from many different groups within an organization. Supply Side, MRO Stores, Engineering, Procurement, Maintenance, Management, Operations, and Training must all understand the strategic value in reliability efforts and cooperate with each other. Otherwise, failure and unsustainability may be guaranteed.
If the answer to the question is that the “Reliability Engineer” and/or “Global Reliability Leader” are the individuals responsible, then your journey may not be complete. Your organization should have training in place to demonstrate the value and create understanding in all of these groups about reliability. Procedures should be in place to ensure that proper reliability best practices are considered in the design, procurement, installation, operation, and maintenance. Failure to do so will result in increased life cycle costs of the equipment, reduced capacity, and reduced profits.
Remember that your maintenance department cannot overcome poor equipment design, installation, or operation.
by Trent Phillips CRL CMRP - Novelis
Guest post by Shon Isenhour, CMRP, CAMA, CCMP, Founding Partner at Eruditio LLC
So if you could sum up the common areas of focus during reliability improvement efforts what would they be?
The thought behind this blog post was if someone asks us what we are doing or what all is involved in a reliability improvement effort, how can we give them the scope in a concise, and memorable way. This could be used early on in the discovery or kick-off phase to outline without overwhelming.
I have listed nine things that I would focus on and they all start with P for ease of remembering:
Predictive Maintenance
Using technology to understand equipment condition in a noninvasive way before the functional failure occurs
Example: Vibration, Ultrasonic, Infrared
Preventive Maintenance
Traditional and more invasive time based inspections which should be failure mode based
Example: Visual Inspection of gears in a gear box
Precision Maintenance
Doing the maintenance craft to the best in class standards to prevent infant mortality
Example: Alignment, Balancing, Bolt Torquing
Process
Clear series of steps to identify, prioritize, plan, schedule, execute, and capture history with who is responsible for each
Example: Work Identification Process, Root Cause Process. Work Completion Process
Problem Solving
The process for understanding the real causes of problems and using business case thinking to select solutions that reduce or eliminate the chance of recurrence
Example: Root Cause Analysis, Fault Tree, Sequence of Events
Prioritizing of Work
The process of determining sequences of work as well as level of effort using tools like equipment criticality and work order type
Example: RIME index
Parts
These are the processes required to have the right part at the right time in the right condition at the right place for the right cost
Example: Cycle counting process, proper storage procedures, kitting process
Planned Execution
This piece is about taking the identified work and building the work instructions, work package and collecting the required parts, and then scheduling the execution.
Example: Job Packages, Schedules, Gantt Charts
People
This is where we deal with the change management and leadership portion which is required in order to truly make a change to the organization
Example: Situational Leadership, Communication Planning, Risk Identification, Training
So here are my nine “Ps” that you can share as early communication to get your organization on board with your reliability efforts and develop the Profit we all want.
What would you add?
by Yolanda Lopez
Published by Uptime Magazine – August / September 2016 Issue
The foundation of any great reliability effort is the reliability culture within the organization that sustains it. Everybody within the organization must be aligned with its ultimate goals and mission for the reliability effort to succeed. Therefore, the mission and values must be clearly communicated, with reasonable expectations for compliance.
A holistic approach to reliability-centered maintenance (RCM) relies on good asset condition management (ACM). This, in turn, relies on accurate condition-based maintenance (CBM), which can only happen with good data. Planning and scheduling (Ps) personnel cannot do their job properly if the maintenance technicians do not feed good data into the system in a timely manner. So, one of the first steps must be to invest in a good enterprise asset management system (EAM) or computerized maintenance management system (CMMS), train all plant personnel in how to use it effectively and impress upon them how they as individuals are important to the overall reliability effort. Remember, the reliability effort relies as much on good data as the culture of cooperation that stands behind it and supports it. Everybody in the organization must understand the importance of their individual role in the wider mission of the organization and, in particular, their interaction with this data system.
Plant management must understand and respect the fact that the boots on the ground (i.e., their technicians and operators) are their best source of information. They are the ones that wrestle with the day-to-day problems and fix them. They know how the machines should sound, smell, and feel. Respect their expertise and opinions. Train your technicians. Invest in quality competency-based learning (Cbl). The knowledge and experience gained will pay off multifold in advancing the entire reliability effort. Give them the tools to do their job right. This means buying a good laser shaft alignment system, vibration analysis tool, and ultrasound leak and corona detection system. This CBM approach will allow your organization to optimize the preventive maintenance effort (Uptime Element Pmo) required to deal with the problem.
Read the full article to learn how you too can take your reliability efforts to the next level within your organization.
by Alan Luedeking CRL CMRP
The maintenance and reliability world is filled with key performance indicators (KPIs). Properly tracking KPIs can be challenging due to difficulties in obtaining accurate data and the time required to obtain them. The key is to pick KPIs that will help you identify and drive the behavior that you need to change right now. As advances are made, additional KPIs can be added which help identify and drive additional behavior changes and improvements.
It is very important to understand that KPIs can lead to false-positive indications and never actually result in value-added or sustainable improvements within your organization. You must understand and address the true root causes behind a deficient KPI and eliminate them.
For example, mean time to repair (MTTR) can be a very good indicator leading to great improvements.
Unfortunately, this indicator can also be harmful if misunderstood or given the wrong improvement focus. What if individuals decide to take deleterious shortcuts to quickly get a machine operational again? MTTR may seem to improve on that machine, but did overall asset health and reliability really improve, in a meaningful way that provides real value back to your organization? These shortcuts may actually lead to additional machinery failures and greater downtime.
MTTR could be an indication that maintenance staff requires training on how to properly repair the machine. Too short and perhaps unwanted shortcuts are being taken. Too long may indicate that excessive time is being wasted hunting for tools or spare parts due to a lack of proper planning and/or kitting. Is a detailed and efficient work plan available, to guide your maintenance staff incorrectly repairing the equipment? MTTR, if properly used and tracked can point you toward areas of substantial improvement.
Never forget to determine and address the root causes of equipment failure. Doing so may eliminate the need to work on the equipment in the first place. Prevention is always the best way to drive sustainable improvements in uptime and capacity.
Beware of driving improvements in KPIs for the wrong reasons. This can lead to a false sense of progress that never brings about real changes and advancements in reliability to your organization. Ensure that you understand the real variables driving the KPIs you have selected. Don’t let your chosen KPIs give you a false sense of improvement!
by Trent Phillips CRL CMRP - Novelis
Did you know that equipment PMs (Preventive Maintenance) tend to become more expensive over time? Why does this happen? For example, additional maintenance steps tend to be added to a PM as time passes. The machine configuration (design installation) changes and the PMs are never updated to reflect these modifications. Some PMs are not written correctly in the first place. All of this means that unnecessary maintenance is performed on your machines costing a lot of resources and money for a very long time. These are just some of the reasons PMs can be costly.
RCM and FMEA functions usually cost more money upfront and tend to be avoided as a result. However, these functions can clearly identify what maintenance actions should be performed on equipment and guide you to steps that will avoid maintenance issues. Condition Monitoring is another tool that works directly with RCM and FMEA functions to reduce PM activities and drive better equipment performance and reliability. These activities may cost more upfront versus a PM but will be much more cost-effective in the long run.
by Trent Phillips CRL CMRP - Novelis
Can a Reliability Engineer or Reliability Manager make a facility or organization reliable? This is a very important question that may be worth discussing within your organization to ensure proper expectations and success.
A more practical definition of reliability may be:
Equipment performs the way you want it to when you want it to”.
Reliability is very easy to define, stuff but achievement of this simple goal is complex and unfortunately unattainable for many organizations. Reliability requires a holistic approach that involves the complex interaction of Maintenance, see Operations, Supply Chain, Engineering, Procurement, Management, Process, and Vendors. Consistency, focus, and strategic implementation directly correlate to the success of any effort and this is true for your reliability efforts. Therefore, a consistent and strategic top-down focus is required from management and throughout each of these groups. Organizational misalignment leads to competing groups and will make sustainable reliability within your organization extremely difficult, and maybe even impossible to achieve.
Reliability Engineers and Managers can support reliability through leadership, training, tools, etc. However, the answer to the question is that everyone within your organization is responsible for reliability. It is critical that everyone within an organization understands this and that reliability is made a goal for each of these groups with defined metrics to track understanding and achievement.
So, who owns equipment reliability in your plant? The answer is Everyone!
by Trent Phillips CRL CMRP - Novelis
As Published by BIC Magazine December 2015 issue
A world-class reliability program is not achieved overnight, yet you must start somewhere. Your first step is to vest your entire human capital in its success. Reliability is a culture, not a goal, and it flows from the top down.
Therefore, executive sponsorship with integrity and enforcement is a must. Obtain buy-in to the culture of reliability from everybody in your organization, or the effort is doomed to fail. Start with this realization, and your reliability effort will ultimately succeed, and you and your stakeholders will reap its rewards.
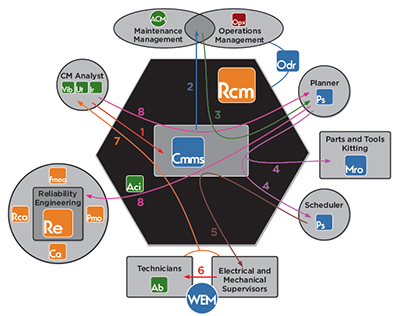
The reliability workflow must be well organized and underpinned by a Computerized Maintenance Management System (CMMS). Let’s look at how it works in a world-class program.
Ultrasound analysis detects a bearing fault in a critical motor early in the P-F curve. The analyst enters this data in the CMMS and trends it. The analyst decides to request a work order with recommendations. This is Stage 1 in the work order process.
The work order is now reviewed by both maintenance and operations, thereby ensuring buy-in from operations as well. This is Stage 2. This review process ensures only truly needed or valuable work is approved. Also, older open work orders can be combined with this one to further streamline planned activity on the asset. For instance, an earlier work order was created to align the machine, but the work was never carried out, resulting in the bearing damage the ultrasound analyst has now detected. The review process would catch the older open order and add it to the present order. This would prevent the millwright from going out to align the machine tomorrow only to have a repair technician go out the following week and repair the motor but do no alignment on it. This review process tries to eliminate inefficiency, duplication, and detrimental work sequences.
Stage 3 assigns the work order to the maintenance planner for action. Only approved and truly necessary work enters the planner’s backlog. The planner ensures work is properly prioritized. Two things are needed: The criticality ranking of the asset (ascertained from systems’ criticality analysis) and its operational criticality. Both of these factors can be multiplied together to create a more accurate prioritization of the workflow. The planner creates a new work plan if needed and should consult with maintenance supervisors and technicians; valuable insights may be gained into what parts, tools, and equipment should be specified in the work plan. Next, the planner orders the maintenance, repair and operating materials (MRO) spares, and tooling required to complete the job and verifies the parts are available and kitted (best practice). The planner should not concern himself with scheduling.
Now on to Stage 4: assignment to the scheduler. The scheduler allocates the HR and necessary time to accomplish the task, with a cushion for unforeseen complications. He too should consult with the maintenance supervisor and technicians to obtain cooperation and buy-in to the schedule. Coordination with operations is crucial. Operations “owns” the equipment and must sign off on the schedule to bring the asset down.
Stage 5 assigns the order to the appropriate maintenance and electrical supervisors, who in turn assign specific tasks in the work plan to their respective repair technicians, electricians, and millwrights, and verify MRO spares has delivered the parts kit to the proper location.
Now the work order enters Stage 6: the work execution phase. Once the technicians have completed the work, they report to their supervisors, who return the asset to active duty status in the system. Operations is notified the asset is ready for service, and MRO spares is notified of any unused parts and supplies that should be returned and reintegrated into the MRO spares inventory. Technicians and supervisors should feed their observations and data into the CMMS system.
Stage 7 sees the ultrasound analyst performing follow-up data collection on the asset to ensure all is well. The work now goes back to the planner to be formally closed. This ensures all important data has been accumulated and distributed within the system, enabling key performance indicators to be updated.
As good data accumulates, reliability engineering will use it to improve the entire reliability and maintenance process, discover frequent failure patterns, identify training needs, drive out defects, streamline production and help to improve the design process. As the plant becomes more efficient and productive, greater resources can be allocated to defect elimination and strengthening condition-based maintenance technologies, further impelling the transition to a proactive, reliability-centered culture. Reliability is a never-ending journey of continuous improvement.
by Alan Luedeking CRL CMRP
Traditionally, company profits have been maintained and increased through three primary means:
- Increase the price of goods and services sold.
- Increase the amount of goods and services sold.
- Reduce the costs of goods and services sold.
Options 1 and 2 can be very difficult or even impossible to implement in a competitive market. Therefore, option #3 may seem like the only viable option. Reductions in costs can be accomplished in many ways. Some are drastic attempts such as reducing product quality or the number of employees. It is almost impossible for companies to achieve true long-term profit gains in these ways because those gains are usually short-lived.
What can you do to help your company increase profits in the competitive world we live in, and provide greater stability in your job? Reduce the costs of goods and services produced (option #2) in a way that you or your facility may not have previously considered. You can do this by:
- Improving equipment reliability through implementing Condition Monitoring reliability practices (RCM, FMEA, RCFA, etc).
- Ensuring the correct maintenance activities are planned, scheduled, and completed on time.
- Ensuring that the correct spare parts inventory is available and kitted when the work is scheduled and executed.
- Ensuring that value-added PMs are created and completed on the equipment.
- Ensuring that reliability-based engineering is completed. Maintenance cannot overcome poor design and installation.
- Ensuring operational activities that support maintenance and reliability are followed. Maintenance and Operations should work as partners and not as competitors.
- Supporting those in your facility that are working toward these efforts.
- Make sure that the right work is being done on the right equipment. This requires prioritizing based on a thorough understanding of equipment criticality, understanding how and why your equipment can fail, what really needs to be done to keep it operational upon demand, etc.
All of the above efforts can help your facility reduce maintenance costs and the cost of goods and services produced. This could be the difference between being the leader in your market or watching your job, profit and company suffer.
by Trent Phillips CRL CMRP - Novelis
Every day more and more of the maintenance and reliability community is transitioning into using tools such as LinkedIn, Twitter, blogs, and wikis. There is now a wealth of information out there for those who know how to find it. In his presentation “Who Gives a “Twitter” About Being “LinkedIn” to Reliability? Ways to Improve Plant Reliability with the Internet” at the SMRP-2013 Conference in Indianapolis, Shon Isenhour discussed what these smart people are doing, how they are doing it, and what they are gaining for their efforts.
Shon gave us real examples of problems solved via the Internet and how others can join in to find solutions to their challenges. He wrapped up his session by providing 10 ways to put the Internet to use immediately within your plant. Here they are, in no particular order:
1. For RCA preparation prior to getting the team together, pull equipment documentation and any history available via Google.
2. Search bulletin boards and user group pages for common equipment failures others are experiencing using Google. Verify that these are part of your Equipment Maintenance Plan (EMP) and your Reliability Centered Maintenance (RCM) and Failure Mode and Effects Analysis (FMEA) efforts.
3. Locate spare parts for obsolete equipment via eBay and Google.
4. Locate new vendors and service centers for existing parts via Google.
5. Identify physical defects with pictures of similar failures from Google images.
6. Find equipment vendors’ websites via Google… It is not always so obvious.
7. Read about additional vendor, equipment, part, or product characteristics information on Wikipedia prior to and during an RCA.
8. Follow your common vendors on Twitter to be in the loop with their most recent product releases and updates.
9. Read the blogs of people interested in the same topics or that deal with the same issues you face.
10. Read the various trade publication websites for articles that target the problems you are facing.
Bonus: If you don’t find the answer in any of these places, then post your question to LinkedIn and see what you get.
Thanks to Shon Isenhour, CMRP with Allied Reliability Group for sharing his presentation and knowledge with us.
Visit Shon’s Blog at: www.reliabilitynow.com
Join the LUDECA Machinery Alignment | Vibration | Balancing LinkedIn Group
Follow LUDECA on Twitter
by Ana Maria Delgado, CRL
When a facility goes into a planned outage, many events needed to happen before the company gets to this point.
The following are some interesting facts and activities a plant will undergo before an outage:
• Planning for a major outage begins when the previous outage is completed.
• Planning and scheduling play a major role. Prioritizing which jobs need to be completed, and in which order, and obtaining the necessary permits and work orders.
• Most of the maintenance budget of a facility is spent on outages. With proper planning and scheduling, costs can be reduced, rather than reacting to imminent problems.
• Several factors dictate when an outage will take place: Weather, the flow of incoming raw material, demand for product/service, consensus with the local utility, cost, and manpower.
• Preparing or ordering auxiliary equipment and/or replacement components. Identifying lead times helps with scheduling.
• Preparing scaffolding permits and crew will help indicate the length of the outage.
• In most cases, operations will control the work, and maintenance performs it.
• Determining the need for contract work, and in-house work. This will identify the available manpower and labor hours.
• Scheduling visits from manufacturer’s representative for critical equipment. This will help with warranty issues, and ordering necessary components.
• Safety programs and procedures must be implemented.
• Implementing an RCM program may help more planned work and fewer unexpected outages.
• Identify how many shifts will work during the outage, and hire the proper crew.
by Adam Stredel CRL
Tie condition monitoring into RCM and RCA.
Use the information to assess machine health.
In brief:
- Where does CM come into play in the RCM process?
- RCM draws clear and accurate boundaries around a physical asset.
- CM is not only easy to incorporate into both RCM and RCA but is essential in achieving RCM and RCA success.
A successful reliability-centered maintenance (RCM) program or root cause analysis (RCA) is difficult to imagine without condition monitoring (CM). RCM is a process that has been around for a number of years and has proven successful because of the sheer logic of the process.
Just what is RCM? We will forgo any formal definitions and answer the question by looking at how RCM works. Succinctly, RCM draws clear and accurate boundaries around a physical asset. All things contained within these boundaries are then subjected to the RCM analysis. All of the functions of that asset are then identified. In other words, what does the asset do? Then all of the ways that those functions can fail are identified and analyzed. Once this is done, tasks are developed to prevent or minimize the consequences of the failures that are likely to occur and would have a negative consequence. Simply stated, an analysis is performed and then something is done (tasks) to keep the asset functioning to a required level. It is difficult to envision a process more logical than RCM for maintaining physical assets (machinery).
Read my entire PLANT SERVICES article “Tie condition monitoring into RCM and RCA”
by Bill Hillman CMRP
Condition monitoring is the process of monitoring a parameter of condition in machinery, such that a significant change is indicative of a developing failure. Ironically most Condition Monitoring Programs often fail and here are some reasons why:
• Inappropriate use of “Low Tech” or “Low Priced” condition monitoring (CM) technologies
• CM technologies are purchased and results are magically expected to appear
• Use of “Part-Time” personnel for CM efforts
• Insufficient (or no) training provided initially and continually
• Do not establish certification criteria for employees
• Insufficient “LOA” (level of awareness) training to plant employees so that they understand the importance of CM efforts
• Failure to create sufficient collection schedules (routes)
• Apply CM technologies to a limited amount of plant equipment or the wrong equipment
• Over dependent upon a single CM technology
• Improper or outdated alarming criteria
• Improper utilization of the CM technology and software
• Improper database setup
• Poor documentation, reporting, and communication of the results
• No metrics to provide feedback
• No follow-up inspections on repaired equipment
• No acceptance inspections on new equipment, lubricants, etc.
When Condition Monitoring programs fail, equipment reliability fails too. Don’t let your program become another statistic or “flavor of the month”. Use proactive tools like Reliability Centered Maintenance or other techniques to develop a basis for the Condition Monitoring strategies you deploy. Work to ensure that the reasons listed above don’t become your reasons for failure. If you need help, please let us know because we measure our success on your success. What other items would you suggest to achieve and sustain success?
by Trent Phillips
The Reliability Support Team at the Eastern Processing Facility located at Cape Canaveral Air Force Station, FL, won Uptime Magazine’s Best Design for Reliability Program award.

During the design phase of their program, the team was challenged with the implementation of Reliability-Centered Maintenance (RCM) principles and Precision and Predictive techniques from construction through commissioning. These have proven to be the most advantageous with regard to failure mode consequence reduction.
Congratulations to Frank Saukel, Garry Pell, and their team for this prestigious award and a job well done!
Program Highlights
1. Eastern Processing achieved Failure Mode Reduction with added redundancy.
2. They redesigned the facilities’ Reverse Osmosis Water System.
3. They performed Asset Prioritization based on safety, environmental, mission impact, and probability of failure studies.
4. They trained technicians and engineers on RCM. In the words of Garry Pell: “Don’t expect to gain tribal knowledge if you don’t invite them into the Teepee. Get your people involved from engineering to safety, from shipping to operations.”
6. They developed all maintenance procedures based on RCM decisions.
7. They identified the Predictive Maintenance (PdM) technologies and tools they needed, met with different vendors at different IMC Conferences, then focused, implemented, and trained on 1 or 2 maintenance and
Condition Monitoring (CM) technologies annually, including:
• Lubrication analysis
• Vibration analysis
• Laser shaft alignment
• Infrared thermography
• Ultraviolet thermography
• Electric signature analysis
• Ultrasound
Many discrepancies were corrected using these PdM and CM technologies. According to Frank Saukel, “Every one of the PdM technologies has paid for themselves.” For instance, they identified misalignment and motor structure resonance conditions using their VIBXPERT® vibration analyzer on several of their water pumps which had been aligned by a contractor.

Every pump was found to be bolt-bound and base-bound. They realigned all their pumps to excellent tolerance with their ROTALIGN® ULTRA laser alignment tool.

They also found and corrected electrical deficiencies with ultraviolet thermography and detected sub-grade piping leaks with ultrasound. Their precision lubrication program included oil analysis, with a resulting reduction in the number of lubricants, minimization of cross-contamination, and implementation of a color-coded system for easy machine identification and the use of accessories to control moisture. Learn more…
by Ana Maria Delgado, CRL