Today’s more evolved ultrasound data collectors present results that take reliability practitioners beyond the single decibel. Using only an overall dB value may indicate something inside the machine has changed since the last readings were taken. But it provides no additional insight to determine what type of defect may be present.
Moreover, a single dB only provides a useful trend if the inspector has control of the acquisition time during data collection. Acquisition time needs to be adjusted in concert with the speed of the machine. More time for low-speed applications and less for high. The aim should be to capture a minimum of 2-3 full shaft rotations.
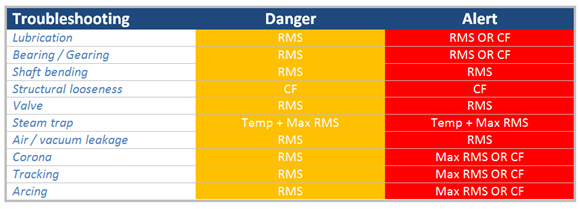
The SDT270 takes inspectors beyond the single decibel by presenting ultrasound data in terms of machine condition. We call them Condition Indicators and there are four (RMS, Max RMS, Peak, and Crest Factor (CF)) and are abbreviated as 4CI. Ultrasound identifies defects in machines when those defects produce one or more of the following phenomena: FRICTION, IMPACTING, or TURBULENCE (FIT).
Some examples:
- A bearing that requires lubrication will present higher levels of friction. Therefore, an RMS danger alarm will be triggered at 8 dB and an RMS/CF alarm when severity increases.
- A bent shaft produces higher levels of friction and therefore presents danger and alert warnings with the RMS condition indicator.
- Electrical defects such as arcing, tracking, and corona are first alarmed with the RMS condition indicator and severely alarmed with Max RMS and CF.
- A faulty steam trap is detected with an elevation in Temperature and Max RMS.
Traditional ultrasound is useful for trending decibel levels that alert us when machine condition changes. Evolved ultrasound goes beyond the single decibel to recruit Condition Indicators that help inspectors determine the type of defect that is creating the alarm. SDT’s Four Condition Indicators demonstrate how ultrasound must be used for both defect alarm and identification.
by Allan Rienstra - SDT Ultrasound Solutions
The maintenance and reliability world is filled with key performance indicators (KPIs). Properly tracking KPIs can be challenging due to difficulties in obtaining accurate data and the time required to obtain them. The key is to pick KPIs that will help you identify and drive the behavior that you need to change right now. As advances are made, additional KPIs can be added which help identify and drive additional behavior changes and improvements.
It is very important to understand that KPIs can lead to false-positive indications and never actually result in value-added or sustainable improvements within your organization. You must understand and address the true root causes behind a deficient KPI and eliminate them.
For example, mean time to repair (MTTR) can be a very good indicator leading to great improvements.
Unfortunately, this indicator can also be harmful if misunderstood or given the wrong improvement focus. What if individuals decide to take deleterious shortcuts to quickly get a machine operational again? MTTR may seem to improve on that machine, but did overall asset health and reliability really improve, in a meaningful way that provides real value back to your organization? These shortcuts may actually lead to additional machinery failures and greater downtime.
MTTR could be an indication that maintenance staff requires training on how to properly repair the machine. Too short and perhaps unwanted shortcuts are being taken. Too long may indicate that excessive time is being wasted hunting for tools or spare parts due to a lack of proper planning and/or kitting. Is a detailed and efficient work plan available, to guide your maintenance staff incorrectly repairing the equipment? MTTR, if properly used and tracked can point you toward areas of substantial improvement.
Never forget to determine and address the root causes of equipment failure. Doing so may eliminate the need to work on the equipment in the first place. Prevention is always the best way to drive sustainable improvements in uptime and capacity.
Beware of driving improvements in KPIs for the wrong reasons. This can lead to a false sense of progress that never brings about real changes and advancements in reliability to your organization. Ensure that you understand the real variables driving the KPIs you have selected. Don’t let your chosen KPIs give you a false sense of improvement!
by Trent Phillips CRL CMRP - Novelis
How do you obtain the desired return on your assets? Availability, maintainability, and reliability are foundational elements required for a proper return on your equipment. Condition Monitoring is a tool that can help you build these elements and obtain the desired returns. Condition Monitoring can be completed while equipment is running to maximize uptime and help provide better overall reliability. Conditional changes can be identified before functional failures that result in downtime occur, preventing other unwanted consequences.
Unneeded work can be avoided (unnecessary PMs, failures, etc.), and better planning and improved scheduling achieved through CM.
Use Condition Monitoring as a means to build a solid foundation for your facility!
by Trent Phillips CRL CMRP - Novelis
Companies spend lots of money, time, and effort on systems to document what needs to be done, what should have been done, failures that occurred, etc. Unfortunately, these systems usually show and document the point of failure (F) and not the point of conception (P) for a problem. These are examples of downtime systems and are important for success.
Does your company invest in uptime systems and processes? What is an uptime system or process? These systems help your facility identify the point of conception (P) of a problem. This is very important because it means your facility has more time to mitigate a problem before it results in unwanted consequences (injury, downtime, increased costs, poor quality, less main profit, etc.)
Condition monitoring (CM), reliability efforts, proper planning, and scheduling, kitting, effective PMs, reliability-based engineering, etc., will reduce the amount of information that must be entered and tracked through the downtime systems that have been heavily invested in. The results can be extremely rewarding.
What uptime systems and processes does your facility utilize?
by Trent Phillips CRL CMRP - Novelis
March 2016 · Empowering Pumps Magazine
“Work smarter, not harder” is a statement we have all heard before, but who has the time to think about smarter ways to work when there is so much work to be done? Some maintenance professionals are so busy trying to keep their operation running smoothly that they often address equipment issues “reactively”. This might make maintenance teams feel more like “firemen” as they respond to in-the-moment needs. So how does a company become less “reactive” and more “proactive”?
Read the full article: Maximize Uptime with Asset Condition Management to better understand the key components of an Asset Condition Management (ACM) Program and how core technologies like Alignment, Balancing Vibration Analysis, and Ultrasound Testing can help you increase uptime.
by Dave Leach CRL CMRT CMRP
May 2016 · Plant Services Magazine
Like a lot of reliability engineers, Joe Anderson, former reliability manager at the J.M. Smucker Co., appreciated – in theory – that precise pulley alignment is critical to preventing vibration problems and ensuring successful operations.
My understanding was, ‘Yeah, we need to do it,’ ” Anderson says. “But you always have these excuses.”
When the Smucker’s plant at which Anderson worked launched a dedicated vibration monitoring and control program a year-and-a-half ago, though, Anderson quickly became a convert to making precision alignment a priority.
The plant purchased a vibration analyzer (VIBXPERT®) and laser alignment tool (the SheaveMaster® Greenline) from Ludeca to help aid in identifying machine defects that appeared to be linked to vibration caused by misalignment. Laser alignment allowed for correcting vertical angularity, horizontal angularity, and axial offset – the three types of misalignment – simultaneously. Whoever was using the laser alignment tool, then, could be sure that adjustments made to correct one alignment problem didn’t create an issue on another plane.
Read the entire article to learn how J.M. Smucker Co. made precision alignment a priority: Get your alignment in line: Don’t jiggle while you work
by Ana Maria Delgado, CRL
Guest post by Karl Hoffower – Condition Monitoring and Reliability Expert for Failure Prevention Associates
Location and placement of your sensors are crucially important when doing predictive vibration analysis.
1) Below is an example of proper sensor installation on a cooling tower gearbox. These two sensors are placed in different directions to follow both the gearbox vibration as well as indicate if the fan blades become unbalanced.

Read Vibration Sensors for Cooling Towers case study from CTC for details on proper sensor installation on cooling towers.
2) This example of poor sensor placement is on a vertical motor using a belt drive for a fin fan.

PROBLEM
- The vibration sensors pictured on the left are attached to one of the motor fins. Watching these sensors, one could visually see the fin and sensors oscillating as if on a trampoline.
SOLUTION
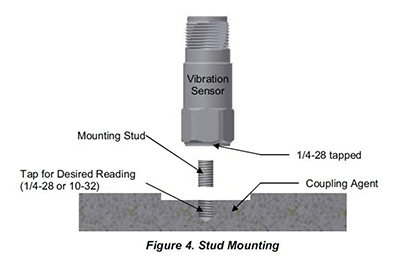
- The choices are to face, drill & tap (see figure #4 below).
- The other option would be to epoxy a mounting pad to the bearing housings. Then screw the sensor into the mounting pad.
3) Another example of poor sensor placement on a 4-20mA shutdown switch on a gas recipient compressor at a facility in Texas.

PROBLEM
{kind=link}
- The vibration sensor (yellow arrow) is a 4-20mA accelerometer used for asset protection in an automatic shutdown setting. It is monitoring the overall vibration levels emanating from the bearings and shaft (red arrow).
SOLUTION
- The better choice would be to use a mounting pad attached to the pillow block bearing.
by Yolanda Lopez
Reposted from RELIABILITYWEB®
- Assemble a team and identify applications for a program
- Justify needs by recognizing key areas where improvement can be benchmarked
- Set written goals for the program
- Establish how ROI will be measured
- Purchase quality ultrasonic inspection equipment
- Invest in certification training at both management and user levels
- Choose a leader to technically carry the program forward
- Establish a system to reward the successes
- Frequently review the progress as part of regular meetings
- Ensure everyone involved is 100% mentally invested in the program’s success
Tip from Hear More: A Guide to Using Ultrasound for Leak Detection and Condition Monitoring by Thomas J. Murphy and Allan R. Rienstra.
To learn more about airborne ultrasound, download a chapter preview of Hear More.
by Allan Rienstra - SDT Ultrasound Solutions
Did you know that equipment PMs (Preventive Maintenance) tend to become more expensive over time? Why does this happen? For example, additional maintenance steps tend to be added to a PM as time passes. The machine configuration (design installation) changes and the PMs are never updated to reflect these modifications. Some PMs are not written correctly in the first place. All of this means that unnecessary maintenance is performed on your machines costing a lot of resources and money for a very long time. These are just some of the reasons PMs can be costly.
RCM and FMEA functions usually cost more money upfront and tend to be avoided as a result. However, these functions can clearly identify what maintenance actions should be performed on equipment and guide you to steps that will avoid maintenance issues. Condition Monitoring is another tool that works directly with RCM and FMEA functions to reduce PM activities and drive better equipment performance and reliability. These activities may cost more upfront versus a PM but will be much more cost-effective in the long run.
by Trent Phillips CRL CMRP - Novelis
There are many tools considered “accurate”. Dial test indicator can measure to the ten-thousandths and gauge blocks can be certified for even tighter tolerances. Even CNC machines can reach ten-thousandth’s accuracy given the right conditions. However, they are tools and they can’t perform to their maximum potential if not used properly or in the right application.
Laser shaft alignment tools follow the same rules. The sensors by themselves have varying degrees of accuracy but how the sensors are used and what application they are used for can vary this accuracy quite a bit. When searching for a “laser alignment system”, don’t be quick to commoditize the term and think all systems are the same just because it uses a “laser”. The most capable systems will work for their intended primary application— general shaft alignment. Should a specialized application arrive, such as an uncoupled spacer shaft with limited rotation, a system that has more functionality will be able to immediately handle the job over a basic system.
LUDECA can assist you in your decision. We provide a network of local solutions providers who are your highly experienced advisors for navigating all of the choices that a quick internet search can provide. They will make sure you know you are getting the right tool for your needs whatever your budget. We also have a team of engineers that will guide you in your applications. All this is provided for free! This is something to consider when purchasing on price alone. We will be there when you need us the most.
So let’s go back to the dial indicators, gauge blocks, and the CNC machine – they are not accurate in use without a trained operator. The same principle applies to laser shaft alignment. Most of our laser shaft alignment systems currently have 1-day free training on-site at your facility by your local solutions provider. Our laser shaft alignment tool is designed to improve your reliability and thereby reduce downtime. Avoid costly mistakes and wasted time by ensuring your operators are well trained to use these tools to their maximum potential.
by Daus Studenberg CRL
Can a Reliability Engineer or Reliability Manager make a facility or organization reliable? This is a very important question that may be worth discussing within your organization to ensure proper expectations and success.
A more practical definition of reliability may be:
Equipment performs the way you want it to when you want it to”.
Reliability is very easy to define, stuff but achievement of this simple goal is complex and unfortunately unattainable for many organizations. Reliability requires a holistic approach that involves the complex interaction of Maintenance, see Operations, Supply Chain, Engineering, Procurement, Management, Process, and Vendors. Consistency, focus, and strategic implementation directly correlate to the success of any effort and this is true for your reliability efforts. Therefore, a consistent and strategic top-down focus is required from management and throughout each of these groups. Organizational misalignment leads to competing groups and will make sustainable reliability within your organization extremely difficult, and maybe even impossible to achieve.
Reliability Engineers and Managers can support reliability through leadership, training, tools, etc. However, the answer to the question is that everyone within your organization is responsible for reliability. It is critical that everyone within an organization understands this and that reliability is made a goal for each of these groups with defined metrics to track understanding and achievement.
So, who owns equipment reliability in your plant? The answer is Everyone!
by Trent Phillips CRL CMRP - Novelis
Most companies focus on repairing equipment after some functional failure has occurred and getting the equipment operational again. Is that the primary focus of your facility? Different studies have been completed by different organizations, which, while the percentages are different, all point to some very consistent and vital information. Design (engineering), installation (contractors, internal resources) and operation of the equipment all introduce equipment defects and drive reliability in your facility. Maintenance cannot overcome poor design, installation, and operation. Your maintenance staff can only deal with (repair) the consequences.
Your reliability efforts should be focused on preventing the introduction of defects in your equipment. This will help ensure equipment reliability leading to lower maintenance costs, increased capacity, and other positive results. Ensure that your equipment is designed, installed, and operated with reliability in mind. Make sure that you focus on the prevention and elimination of equipment defects as well.
by Trent Phillips CRL CMRP - Novelis
Maintenance and reliability professionals track many key performance indicators (KPI’s) to measure the success of their efforts. These indicators can be overwhelming but are necessary to confirm the proper direction and achievement of desired results.
It is important that your CMMS (computerized maintenance management system) has the ability to categorize work orders. Condition monitoring work orders should be categorized by main types and by sub-types (vibration, lubrication, thermography, ultrasonic, electrical, etc.) upon creation within the CMMS.
Your CM and Reliability team should actively track condition monitoring work orders by total created, their type (vibration, lubrication, etc.), status (in process, scheduled, completed, etc.), the average length of time to completion, rejection results, and so on.
These indicators will allow you to ensure that a healthy amount of CM work is available and that this work is given priority, being properly planned, scheduled, and executed. It does no good to detect and report a conditional change in equipment only to have it ignored, not properly repaired, and then result in a functional failure.
Additionally, technology alarm status can be compared to open corrective work orders in your CMMS. For example, a corrective work order should exist addressing each severe alarm condition (red) reported by a CM technology. If a corresponding work order has not been created, then you should ask “Why”? Is it due to a bad technology alarm? Did the CM analyst miss something or fail to report the condition or repair? Or did the planner or scheduler simply overlook or ignore it?
Monitoring these indicators can help ensure that your CM program is providing continual results that will move your reliability efforts forward.
What indicators do you track to determine success with condition monitoring efforts within your company?
by Trent Phillips CRL CMRP - Novelis
As Published by BIC Magazine December 2015 issue
A world-class reliability program is not achieved overnight, yet you must start somewhere. Your first step is to vest your entire human capital in its success. Reliability is a culture, not a goal, and it flows from the top down.
Therefore, executive sponsorship with integrity and enforcement is a must. Obtain buy-in to the culture of reliability from everybody in your organization, or the effort is doomed to fail. Start with this realization, and your reliability effort will ultimately succeed, and you and your stakeholders will reap its rewards.
The reliability workflow must be well organized and underpinned by a Computerized Maintenance Management System (CMMS). Let’s look at how it works in a world-class program.
Ultrasound analysis detects a bearing fault in a critical motor early in the P-F curve. The analyst enters this data in the CMMS and trends it. The analyst decides to request a work order with recommendations. This is Stage 1 in the work order process.
The work order is now reviewed by both maintenance and operations, thereby ensuring buy-in from operations as well. This is Stage 2. This review process ensures only truly needed or valuable work is approved. Also, older open work orders can be combined with this one to further streamline planned activity on the asset. For instance, an earlier work order was created to align the machine, but the work was never carried out, resulting in the bearing damage the ultrasound analyst has now detected. The review process would catch the older open order and add it to the present order. This would prevent the millwright from going out to align the machine tomorrow only to have a repair technician go out the following week and repair the motor but do no alignment on it. This review process tries to eliminate inefficiency, duplication, and detrimental work sequences.
Stage 3 assigns the work order to the maintenance planner for action. Only approved and truly necessary work enters the planner’s backlog. The planner ensures work is properly prioritized. Two things are needed: The criticality ranking of the asset (ascertained from systems’ criticality analysis) and its operational criticality. Both of these factors can be multiplied together to create a more accurate prioritization of the workflow. The planner creates a new work plan if needed and should consult with maintenance supervisors and technicians; valuable insights may be gained into what parts, tools, and equipment should be specified in the work plan. Next, the planner orders the maintenance, repair and operating materials (MRO) spares, and tooling required to complete the job and verifies the parts are available and kitted (best practice). The planner should not concern himself with scheduling.
Now on to Stage 4: assignment to the scheduler. The scheduler allocates the HR and necessary time to accomplish the task, with a cushion for unforeseen complications. He too should consult with the maintenance supervisor and technicians to obtain cooperation and buy-in to the schedule. Coordination with operations is crucial. Operations “owns” the equipment and must sign off on the schedule to bring the asset down.
Stage 5 assigns the order to the appropriate maintenance and electrical supervisors, who in turn assign specific tasks in the work plan to their respective repair technicians, electricians, and millwrights, and verify MRO spares has delivered the parts kit to the proper location.
Now the work order enters Stage 6: the work execution phase. Once the technicians have completed the work, they report to their supervisors, who return the asset to active duty status in the system. Operations is notified the asset is ready for service, and MRO spares is notified of any unused parts and supplies that should be returned and reintegrated into the MRO spares inventory. Technicians and supervisors should feed their observations and data into the CMMS system.
Stage 7 sees the ultrasound analyst performing follow-up data collection on the asset to ensure all is well. The work now goes back to the planner to be formally closed. This ensures all important data has been accumulated and distributed within the system, enabling key performance indicators to be updated.
As good data accumulates, reliability engineering will use it to improve the entire reliability and maintenance process, discover frequent failure patterns, identify training needs, drive out defects, streamline production and help to improve the design process. As the plant becomes more efficient and productive, greater resources can be allocated to defect elimination and strengthening condition-based maintenance technologies, further impelling the transition to a proactive, reliability-centered culture. Reliability is a never-ending journey of continuous improvement.
by Alan Luedeking CRL CMRP
In today’s world, video platform is the way to accomplish effective visual knowledge and a learning mechanism in many organizations. With the use of video, one not only is able to promote products and services but one can also strengthen a culture and demonstrate how-to scenarios easily and quickly.
LUDECA believes in communicating visually to help customers educate and train their personnel on precision skills. For this reason, we are pleased to announce the release of our new microsite www.LudecaVideos.com, which features a Shaft Alignment Know-How series plus a Know-How series for Vibration Analysis and Balancing. The video site features basic terminology, fundamental concepts, advanced measurements as well as product demonstrations. The videos are indexed by category but also searchable by keyword.
We felt there was a need to go back to basics and help educate on precision skills and related technology to improve asset reliability. Following the Uptime Elements™ holistic approach to reliability, alignment and balancing are key components of your asset condition management (ACM) program. We are happy to offer these videos to our customers for their personnel to access and for use in their training programs. We hope this content assists them and others in either improving their reliability program or in getting one started and leads to world-class reliability programs,” —Frank Seidenthal, president of LUDECA.
We encourage you to visit www.LudecaVideos.com and see for yourself the value behind each video.
by Yolanda Lopez
Every year Uptime Magazine recognizes organizations that demonstrate excellence in managing equipment reliability using advanced strategies and technology to determine potential failures and solutions. Last December during IMC-2015 in Bonita Springs FL, I had the pleasure of attending not only the award ceremony but the presentations by the award-winners. It was fascinating to hear them share their pains, the evolution of their programs, their procedures and processes, and the role technology played in the success of their solutions, such as precision alignment and ultrasound, among others. It was personal and very inspirational. I walked away with a few quotes: “Vision without implementation is just a vision.”; “Unity is a powerful thing!”
The buzzword this year at IMC-2015 was “Reliability”. Everybody wants it, everybody needs it but it was made clear that it can’t happen unless we establish Reliability as a set of values, as a belief system for our organizations, remembering that Reliability comes from within, from the people! The award-winners were a testament of these principles with their commitment to Reliability and ensuring that their M&R teams are aligned with their goals and values.

Congrats to all the winners and a very special thank you to our customers Bristol-Myers Squibb, Central Arizona Project, South Gardens Citrus, Merck & Co., Rahway, and Lawrence Livermore National Laboratory for allowing us to be part of their Reliability Journey.
This is an exciting time for our industry and we can all take part in this adventure. It starts with you! Declare Reliability and be part of the culture change.
Some ideas to help you get started:
- Join the Society of Maintenance & Reliability Professionals (SMRP)
- Become a Certified Maintenance & Reliability Professional (CMRP) or Certified Maintenance & Reliability Technician (CMRT)
- Join the Association of Asset Management Professionals (AMP)
- Become a Certified Reliability Leader (CRL)
by Ana Maria Delgado, CRL
Everyone within your organization should be passionate about improving and maintaining equipment reliability.
However, some groups have more or less to gain from that.
Unfortunately, skipping or moving planned work outages, rushing equipment repairs, not allowing proper maintenance activities to occur, and other disruptions are commonplace within many organizations. These are often influenced or controlled by the Operations Department.
The Operations Department within your organization should be extremely passionate and focused on ensuring that proper maintenance and reliability efforts are implemented and maintained. Why? This group has a tremendous amount to lose or gain from asset performance. This group should be an active part of all reliability efforts. The Operations Department should insist on activities like:
- Preventive Maintenance (PM) Optimization
- PM Compliance
- Precision Maintenance
- Root Cause Failure Analysis (RCA)
- Proper Planning and Scheduling (PS)
- Critical Spares Analysis
- Operator Care Activities
You must be a reliability evangelist and constantly provide education and awareness to help the Operations Department and others understand what they have to gain by promoting and insisting on reliability practices. This will help you lead your organization to improved and sustainable equipment reliability.
by Trent Phillips CRL CMRP - Novelis
Who owns equipment reliability in your plant? The answer may surprise you. It is commonly thought that equipment reliability is owned by the maintenance staff in a facility. Is this true? Let’s look at all of the owners of reliability in your plant:
Engineering is responsible for the design of (and often oversees) the installation of new equipment. Your maintenance team cannot overcome poor design and/or poor installation of equipment. They will be tasked to routinely fix the issues that result from improper engineering efforts.
Sales and Marketing have a certain amount of control over equipment reliability. They can affect maintenance schedules, operational schedules, etc.
Purchasing and the storeroom contribute to equipment reliability by ensuring that proper parts are available and kitted when maintenance work is scheduled. Cheap parts, no parts, wrong parts, no kitting, etc., all contribute to maintenance and reliability issues in your plant.
Proper planning and scheduling are critical for equipment reliability. Otherwise, efforts can be misdirected resulting in reactive efforts and reduced reliability.
Operations can do certain maintenance tasks (operator-driven reliability) that allow the maintenance team to focus on more complex tasks and efforts that improve reliability. Operations may not allow proper time to complete required maintenance tasks and drive equipment to the point of failure through poor operation and contribute to reduced equipment reliability.
Management must set the direction and reinforce the achievement of reliability goals. Otherwise, equipment reliability will never be sustainable.
Maintenance staff must ensure that the work is done correctly (within specifications), on time, and with the correct focus. Efforts should be placed on identifying the correct work through Condition Monitoring and proper PM activities. RCM, FMEA, and other activities should be utilized that identify and drive out failure means and truly improve equipment reliability.
So, who owns equipment reliability in your plant? The answer is: Everyone!
by Trent Phillips CRL CMRP - Novelis
Guest post by Fred Schenkelberg, Reliability Expert for FMS Reliability
A natural question to ask when something fails is “Why did it fail”?
The answer is not always obvious or easy to sort out. Some failures result from design errors, others are related to supply chain and assembly issues, and yet others occur because of seemingly random events (accidents, lightning strikes, etc.). As a reliability engineer, my concern is not simply accounting for end-of-life wear out; it is about meeting the operation’s reliability expectations. From design to failure analysis, by considering the range of possible sources I can identify and attend to the root causes that matter.
Consider a circuit board that has a small burn mark where a component exploded off the board. The customer failed to spot the missing part but noticed that certain features were no longer available. The box went dark and no longer powered up. It was dead, so the customer returned it. That is the failure mode – the loss of a feature or function. This is what the customer notices.
The engineer then has to investigate the root cause and identify the failure mechanism.
Failure Mechanisms and Root Cause
Failure mechanisms are the material or software code faults that lead to failure. They include thin insulation leading to dialectic breakdown, contamination leading to corrosion, or faulty code leading to an over-voltage command. Becoming aware of a product failure and starting to determine why it failed is an exploratory process.
The clues to when the failure occurs may help frame the initial investigation.
To answer the “Why did it fail?” question in a useful manner we need to determine the sequence of events that led to the failure. Root cause analysis is a process to determine this chain of events. The cause may be faulty material or assembly, damage, or design error. It may also include poor decisions and human error. Generally, we look for the physical or chemical reason for the failure. However, we should also explore the design, assembly, supply chain, and customer-related processes to ascertain where an error or weakness in the process could have contributed to the failure.
The idea behind seeking out root causes and determining failure mechanisms is to mitigate issues with problematic elements of the product whose failure would lead to product failure.
Types of Failures and Timing
Products fail for many reasons via many mechanisms. Most products have literally hundreds of ways in which they can fail. It is really a race between different mechanisms all vying to cause the failure. Eventually, everything will fail.
One of the first steps in sorting out the specific cause is determining when the product failed. How old was the product when it failed? Early life (e.g., when a product is just bought and installed) failures tend to cause more customer anguish than a product that has provided a long life of useful service. In general, we often talk about three periods of failure:
• early life failures
• random failures
• wear-out failures
The three periods are often depicted with a curve-shaped like a bathtub. The bathtub curve is the aggregate of many potential failures. Some tend to occur early, whereas some occur later. Each individual product has many possible ways in which it can fail and the most likely failure mechanisms may change over time as the product use and conditions change. Keep in mind that the curve is a fiction to explain a hypothetical profile of possibilities of failure over time for a single item.
Each period of failure also suggests a set of possible causes. Although this set is not always accurate, it provides a good starting place when looking for the root cause.
by Yolanda Lopez
Guest post by Fred Schenkelberg, Reliability Expert for FMS Reliability
In a previous posting (”Five Steps to Building a Better Reliability Culture”, posted on 10/06/2015), I discussed equipment reliability, reliability engineering, and reliability management. But this Holy Trinity of reliability does not operate in a vacuum. Creating a sustainable reliability program within an organization requires an understanding of its culture as well as its structure.
Every organization or product is different. The technology, expectations, and environments are all different. Consider two organizations, each of which has a reliability professional well versed in a wide range of reliability tools and processes. One of these professionals provides coaching and mentoring across the organization and encourages every member of the team to learn and use the appropriate tools to make decisions; the other performs nearly all the reliability work independently without support or consultation with team members. It is easy to see that the first organization’s team, being empowered to make decisions about reliability, will be better equipped to meet its reliability goals.
Thus differences in the basic culture of an organization can lead to vastly different approaches to how reliability is incorporated into its operations. An organization that incorporates reliability into its internal processes starting from the design phase will inevitably experience fewer failures and make more efficient use of its design team and suppliers. How the reliability professional functions within an organization have a strong impact on its culture.
The organizational structure of an organization is also intertwined with its culture. There is no single organizational structure that leads to improved product reliability performance over any other structure. Both centrally and distributed reliability teams have successfully created reliable systems. Even the presence or absence of reliability professionals on staff is not an indicator of reliability performance.
Top-performing organizations use a common product reliability language and possess a culture that encourages and enables individuals to make informed decisions related to reliability. Individuals across the organization know their role to both use and share information essential to making decisions. There is an overriding context for reliability decisions that balances the need to meet customer expectations for reliability along with other criteria. Alignment exists among the organization’s mission, plans, priorities, and behaviors related to reliability.
Equipment reliability is not the only element that benefits from a proactive culture. Whether top-performing organizations enjoy a proactive culture that naturally includes reliability activities to make decisions or evolved while improving product reliability to become a proactive organization with collateral benefits for other areas of running the business remains unclear. The latter is more likely since it takes leadership to build and maintain a proactive organization, although some organizations focus on building a proactive reliability program and develop the benefits later in other functions of the business.
Moving the organizational block around the organizational chart may have some value, although it is not directly related to improving reliability. It entails a more fundamental change than developing the reporting structures to transition from a reactive to proactive reliability program.
Once a group of people gets settled into a routine way of accomplishing something, it is not a simple matter to change the process. Doing so requires overcoming organizational inertia. For reliability professionals to implement reliability improvements, overcoming this inertia entails working closely with key influencers, making the current reality visible and accessible, and celebrating successes. Although every organization is different and every situation warrants its own approach, these three paths to overcoming inertia may facilitate the implementation of any proposed changes.
Overcoming organization inertia is one crucial aspect of changing a reliability culture. Some organizations tend to react to reliability issues. Prototype testing and downing events continue to surprise the team. The worst organizations fall into a cycle of always finding someone to blame. Better organizations set out to work to understand the problem and quickly resolve the issue. Some have better ‘fire departments’ than others. However, responding more quickly is often not the best way to deal with reliability. The very best organizations prevent issues from creating surprises in the first place.
Understanding the reliability culture is the first step to changing it.
by Yolanda Lopez